Contextual Object Detection with Multimodal Large Language Models
IJCV, 2024
Paper
Abstract
Recent Multimodal Large Language Models (MLLMs) are remarkable in vision-language tasks, such as image captioning and question answering, but lack the essential perception ability, i.e., object detection. In this work, we address this limitation by introducing a novel research problem of contextual object detection--understanding visible objects within different human-AI interactive contexts. Three representative scenarios are investigated, including the language cloze test, visual captioning, and question answering. Moreover, we present ContextDET, a unified multimodal model that is capable of end-to-end differentiable modeling of visual-language contexts, so as to locate, identify, and associate visual objects with language inputs for human-AI interaction. Our ContextDET involves three key submodels: (i) a visual encoder for extracting visual representations, (ii) a pre-trained LLM for multimodal context decoding, and (iii) a visual decoder for predicting bounding boxes given contextual object words. The new generate-then-detect framework enables us to detect object words within human vocabulary. Extensive experiments show the advantages of ContextDET on our proposed CODE benchmark, open-vocabulary detection, and referring image segmentation.
The Task
Contextual Object Detection
In this paper, we study a new research problem—contextual object detection—that is understanding visible objects within human-AI interactive contexts. In comparison with existing standard object detection, we consider four comprehensive objectives for such a new setting: (i) capacity: being able to handle a human language vocabulary; (ii) description: describing visual inputs from users with informative natural language statements; (iii) perception: locating and associating visual objects with language queries; (iv) understanding: complementing proper words with language hints.
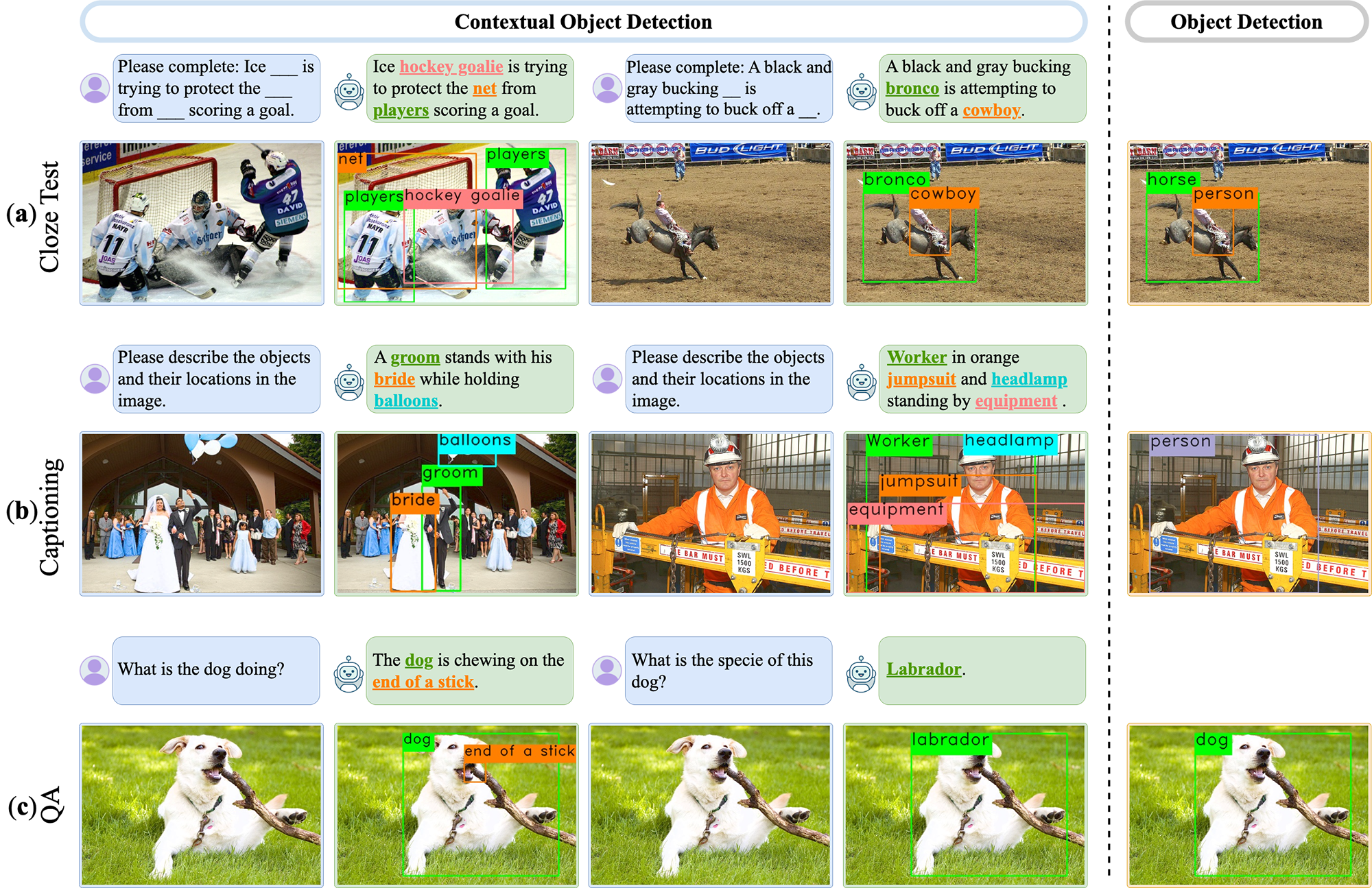
We present a new contextual object detection task include (a) look at the image and complete the masked object names and locations; (b) predict the caption and the boxes of objects existing in the caption; (c) answer a question about the names and locations of objects. Unlike the traditional object detection task that typically focuses on detecting a limited set of pre-defined object classes such as 'person', our task requires predicting more specific names (e.g., 'hockey goalie', 'groom', or 'bride') based on contextual understanding.
Comparison with Related Tasks
| Task | Language Input | Output(s) | Remark |
|---|---|---|---|
| Object Detection | ✗ | box, class label | pre-defined class labels |
| Open-Vocabulary Object Detection | (optional) class names for CLIP | box, class label | pre-defined class labels |
| Referring Expression Comprehension | complete referring expression | box that expression refers to | / |
| Contextual Cloze Test(ours) | incomplete expression, object names are masked | {box, name} to complete the mask | name could be most valid English word |
| Image Captioning | ✗ | language caption | / |
| Contextual Captioning(ours) | ✗ | language caption, box | / |
| Visual Question Answering | language question | language answer | / |
| Contextual QA(ours) | language question | language answer, box | / |
CODE Benchmark
To facilitate research on contextual object detection, we construct a Contextual Object DEtection (CODE) dataset. Specifically, we collected images, bounding boxes and captions annotations from Flickr30k [1] and Flickr30k Entities [2]. We added annotations containing the position information of object names in the caption strings. These object names will be replaced with [MASK] tokens to serve as input in our cloze test setting.
[1] From Image Descriptions to Visual Denotations: New Similarity Metrics for Semantic Inference over Event Descriptions, TACL 2014.
[2] Flickr30K Entities: Collecting Region-to-Phrase Correspondences for Richer Image-to-Sentence Models, ICCV 2015.
The Framework
ContextDet
We present ContextDET, a novel generate-then-detect framework, specialized for contextual object detection. Specifically, it is an end-to-end model that consists of three key modules. First, a visual encoder extracts high-level image representations for given images and produces both local and full visual tokens for further contextual modeling. Second, to effectively model multimodal contexts, we employ a pre-trained LLM to perform text generation, with conditioned inputs of both local visual tokens and task-related language tokens as the multimodal prefix. Third, taking the LLM tokens as prior knowledge for visual detection, we introduce a visual decoder that consists of multiple cross-attention layers, within which we compute conditional object queries from contextual LLM tokens, and keys and values from full visual tokens, to predict the corresponding matching scores and bounding boxes. This allows us to detect contextual object words for a human vocabulary.
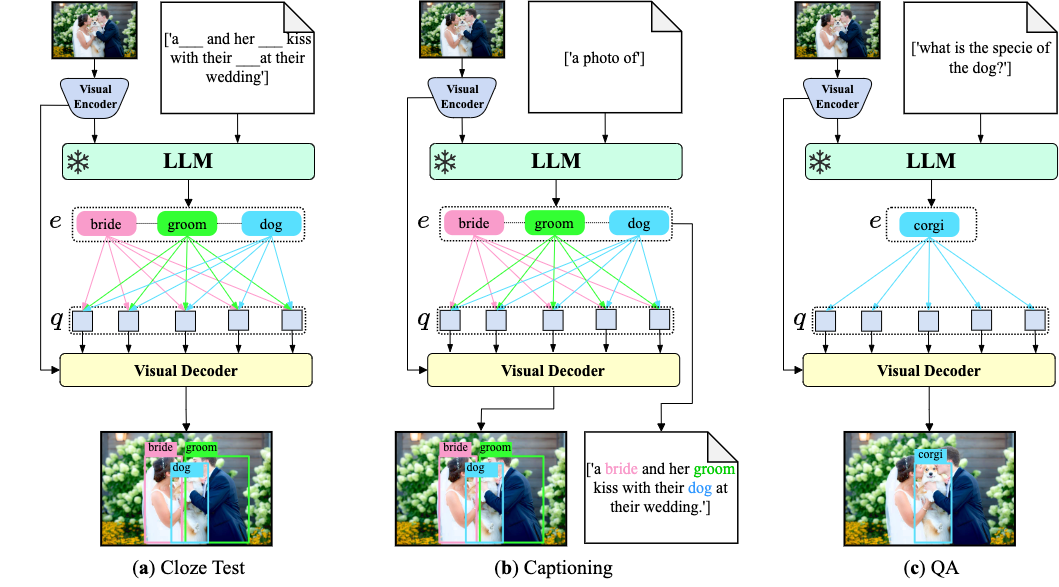
Our ContextDet is a unified end-to-end framework, being capable of taking different language token inputs for different tasks, including (a) cloze test (b) captioning and (c) question answering.
Experimental
Results
We demonstrate the advantages of our ContextDET not only on the contextual object detection but also on open-vocabulary detection and referring image segmentation tasks.
Contextual Cloze Test
| Language Model | Vision Backbone | Acc@1 | Acc@5 | AP@1 | AP@5 | Total #Params (M) | Learnable #Params (M) | Ttrain (s/iter) | Ttest (s/iter) |
|---|---|---|---|---|---|---|---|---|---|
| OPT-2.7B | ResNet50 | 48.7 | 73.8 | 10.2 | 20.5 | 2835 | 183 | 0.437 | 0.224 |
| Swin-B | 54.3 | 78.1 | 13.1 | 25.3 | 2893 | 241 | 0.625 | 0.241 | |
| OPT-6.7B | ResNet50 | 49.2 | 74.5 | 11.1 | 23.4 | 6922 | 263 | 0.448 | 0.248 |
| Swin-B | 54.8 | 78.6 | 13.7 | 26.6 | 6979 | 320 | 0.652 | 0.251 |
Open-Vocabulary Object Detection
| Method | Venue | CLIP | MLLM | Backbone | OV-COCO | ||
|---|---|---|---|---|---|---|---|
| AP50novel | AP50base | AP50 | |||||
| ViLD [3] | ICLR'22 | ✓ | ✗ | ResNet50-FPN | 27.6 | 59.5 | 51.2 |
| OV-DETR [4] | ECCV'22 | ✓ | ✗ | ResNet50 | 29.4 | 61.0 | 52.7 |
| BARON [5] | CVPR'23 | ✓ | ✗ | ResNet50-FPN | 34.0 | 60.4 | 53.5 |
| ContextDet (Ours) | - | ✗ | ✓ | ResNet50 | 36.8 | 65.1 | 57.7 |
Referring Image Segmentation
| Method | Venue | Language Model | Vision Backbone | RefCOCO | RefCOCO+ | RefCOCOg | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| val | testA | testB | val | testA | testB | val | test | ||||
| VLT [6] | ICCV'21 | Bi-GRU | DN53 | 65.65 | 68.29 | 62.73 | 55.50 | 59.20 | 49.36 | 52.99 | 56.65 |
| SeqTR [7] | ECCV'22 | Bi-GRU | DN53 | 71.70 | 73.31 | 69.82 | 63.04 | 66.73 | 58.97 | 64.69 | 65.74 |
| RefTR [8] | NeurIPS'21 | BERT-base | RN101 | 74.34 | 76.77 | 70.87 | 66.75 | 70.58 | 59.40 | 66.63 | 67.39 |
| LAVT [9] | CVPR'22 | BERT-base | Swin-B | 74.46 | 76.89 | 70.94 | 65.81 | 70.97 | 59.23 | 63.34 | 63.62 |
| PolyFormer [10] | CVPR'23 | BERT-base | Swin-B | 75.96 | 77.09 | 73.22 | 70.65 | 74.51 | 64.64 | 69.36 | 69.88 |
| ContextDet (ours) | - | OPT-2.7B | Swin-B | 76.40 | 77.39 | 74.16 | 71.67 | 75.14 | 65.52 | 69.89 | 70.33 |
[3] Open-vocabulary Object Detection via Vision and Language Knowledge Distillation, ICLR 2022.
[4] Open-vocabulary DETR with Conditional Matching, ECCV 2022.
[5] Aligning Bag of Regions for Open-Vocabulary Object Detection, CVPR 2023.
[6] Vision-Language Transformer and Query Generation for Referring Segmentation, ICCV 2021.
[7] SeqTR: A Simple yet Universal Network for Visual Grounding, ECCV 2022.
[8] Referring Transformer: A One-step Approach to Multi-task Visual Grounding, NeurIPS 2021.
[9] LAVT: Language-Aware Vision Transformer for Referring Image Segmentation, CVPR 2022.
[10] PolyFormer: Referring Image Segmentation as Sequential Polygon Generation, CVPR 2023.
Qualitative
Results
We qualitatively evaluate ContextDET using diverse images and objects. The selected images are sourced randomly from the web and are not included in the training data.
Contextual Cloze Test
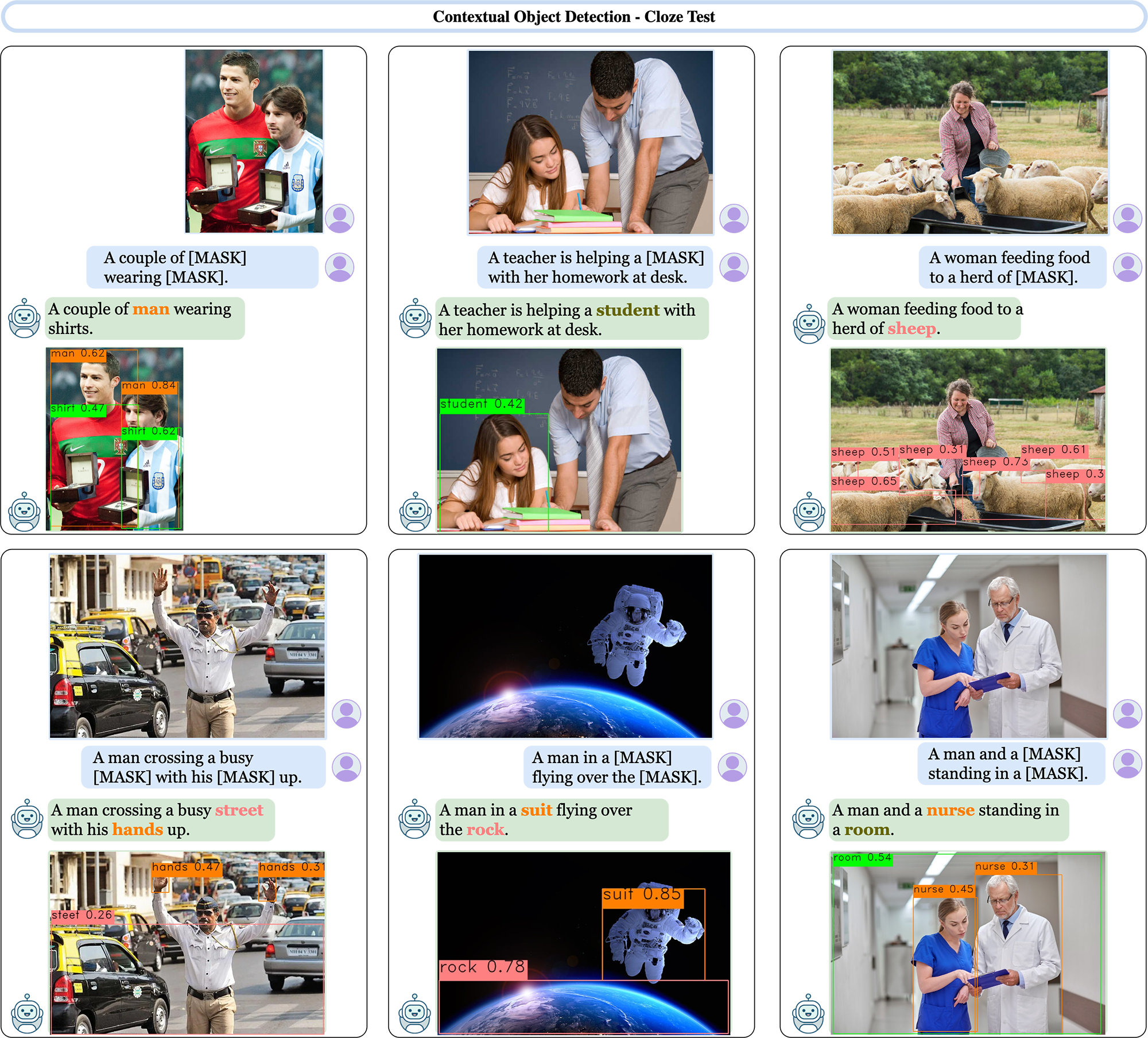
We observe the capacity of ContextDET for complex contextual understanding and generalization to open-world names. ContextDET can reasonably infer the object names to fill the masked tokens, and accurately connect the object names with bounding boxes.
Contextual Captioning
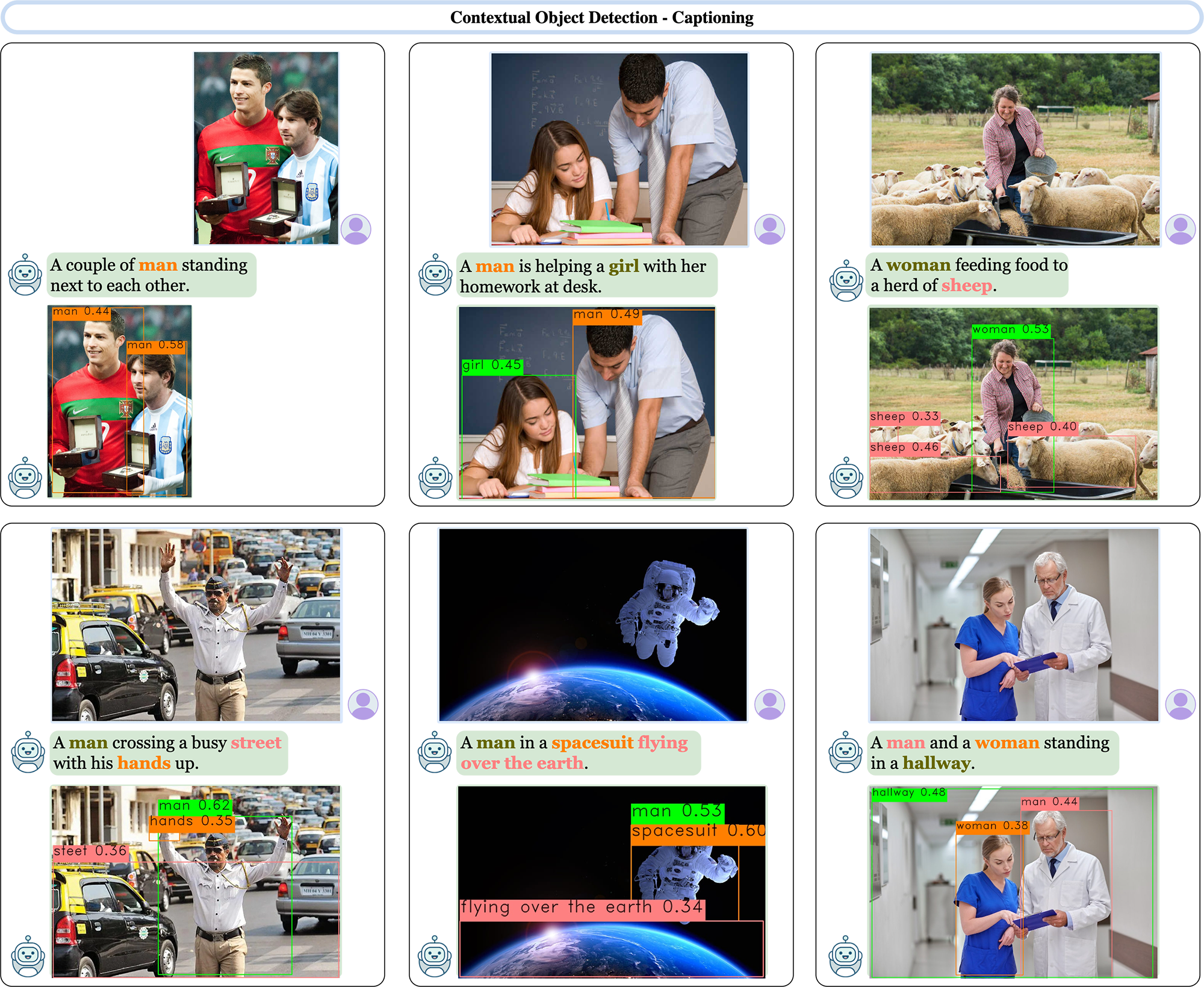
ContextDET is capable of predicting the names and locations of open-world concepts (e.g., 'spacesuit', 'hallway'), which are difficult to detect using previous close-set object detectors
Contextual QA

ContextDET can engage in multi-round question-answering conversations, and predict the bounding boxes of objects mentioned in the dialog history.
Comparison with MLLMs
Existing MLLMs can only generate textual outputs while our ContextDET pushes the boundaries further by providing bounding boxes of objects of interest. In particular, our method allows fine-grained localization of objects of interest specified in the text input, which offers a higher degree of interpretability for vision-language models. Broadly speaking, our method offers new possibilities for various applications requiring both object localization and conversational interaction, e.g., AR/VR systems and robotics.
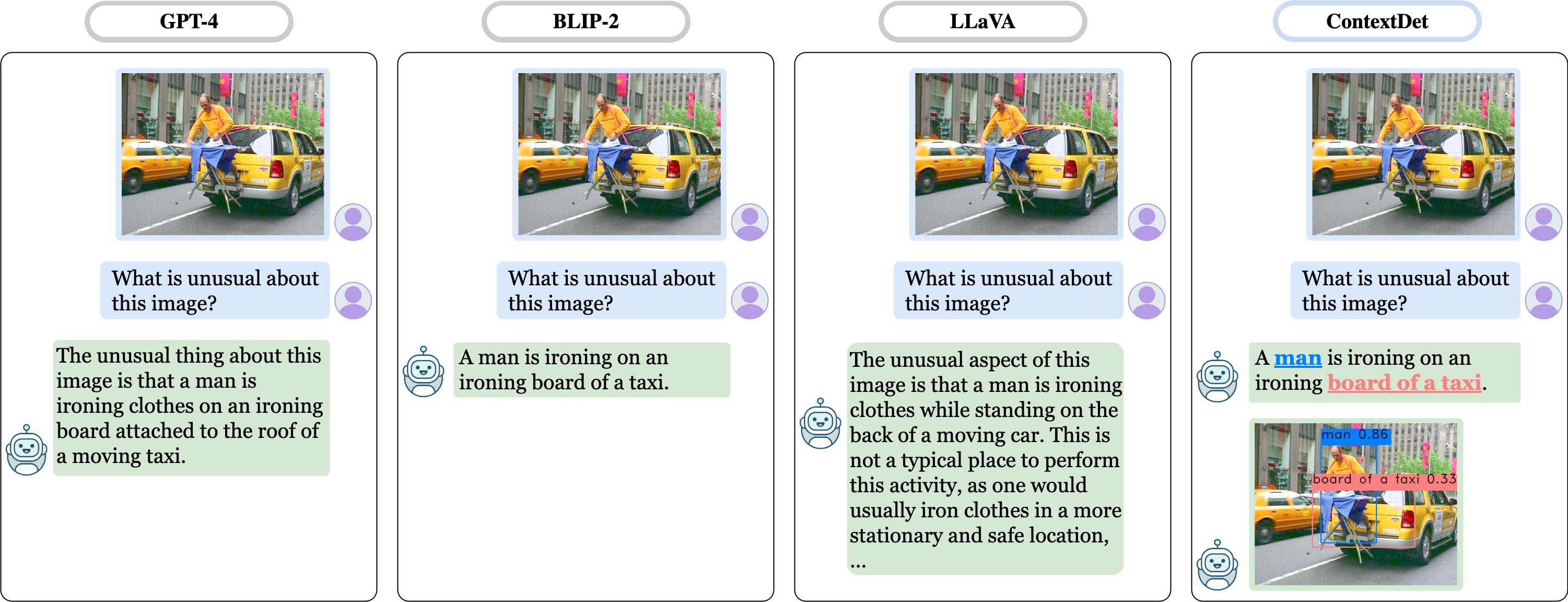
Qualitative examples comparing ContextDET with existing Multimodal Language Models (MLLMs), including GPT-4, BLIP-2, and LLaVA. Our method predicts related bounding boxes for the object names mentioned in the text outputs, (e.g., 'man', 'board of a taxi'), enabling a more comprehensive interpretation for visual-language tasks and paving the way for broader application areas.
Paper
Citation
@InProceedings{zang2023contextual,
author = {Zang, Yuhang and Li, Wei and Han, Jun, and Zhou, Kaiyang and Loy, Chen Change},
title = {Contextual Object Detection with Multimodal Large Language Models},
journal = {International Journal of Computer Vision},
year = {2024}
}
Related
Projects
-
Open-Vocabulary DETR with Conditional Matching
Y. Zang, W. Li, K. Zhou, C. Huang, C. C. Loy
European Conference on Computer Vision, 2022 (ECCV, Oral)
[PDF] [arXiv] [Supplementary Material] [Project Page] -
Extract Free Dense Labels from CLIP
C. Zhou, C. C. Loy, B. Dai
European Conference on Computer Vision, 2022 (ECCV, Oral)
[PDF] [arXiv] [Supplementary Material] [Project Page] -
Unified Vision and Language Prompt Learning
Y. Zang, W. Li, K. Zhou, C. Huang, C. C. Loy
Technical report, arXiv:2210.07225, 2022
[arXiv]
