EdgeSAM
Prompt-In-the-Loop Distillation for On-Device Deployment of SAM
Paper
Abstract
This paper presents EdgeSAM, an accelerated variant of the Segment Anything Model (SAM), optimized for efficient execution on edge devices with minimal compromise in performance. Our approach involves distilling the original ViT-based SAM image encoder into a purely CNN-based architecture, better suited for edge devices. We carefully benchmark various distillation strategies and demonstrate that task-agnostic encoder distillation fails to capture the full knowledge embodied in SAM. To overcome this bottleneck, we include both the prompt encoder and mask decoder in the distillation process, with box and point prompts in the loop, so that the distilled model can accurately capture the intricate dynamics between user input and mask generation. To mitigate dataset bias issues stemming from point prompt distillation, we incorporate a lightweight module within the encoder. EdgeSAM achieves a 40-fold speed increase compared to the original SAM, and it also outperforms MobileSAM, being 14 times as fast when deployed on edge devices while enhancing the mIoUs on COCO and LVIS by 2.3 and 3.2 respectively. It is also the first SAM variant that can run at over 30 FPS on an iPhone 14.

Here, we show the encoder throughput of EdgeSAM compared with SAM and MobileSAM as well as the mIoU performance on the SA-1K dataset (sampled from SA-1B) with box and point prompts.
The Framework
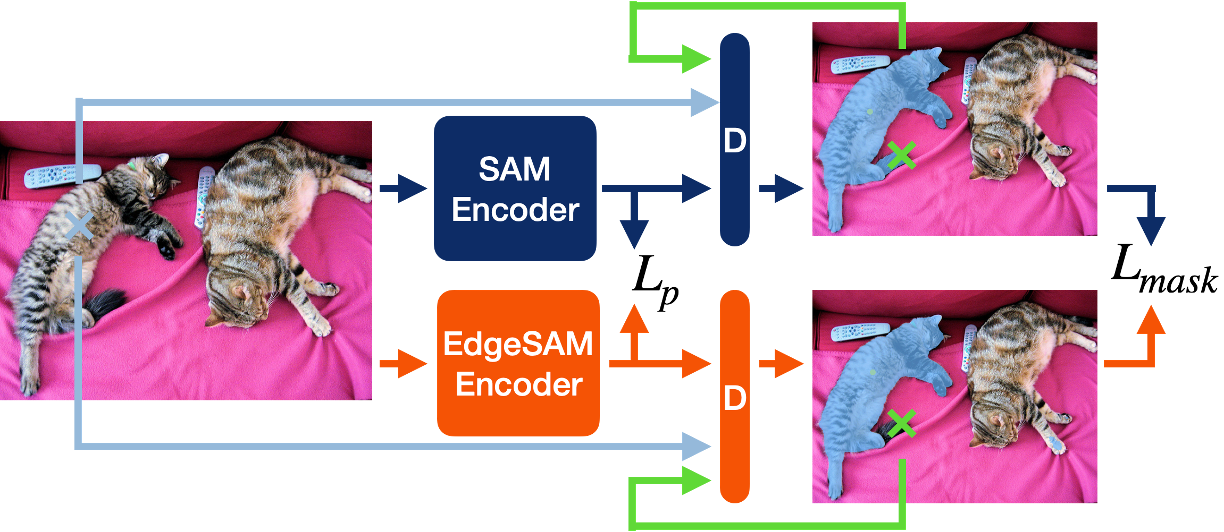
EdgeSAM
The goal of EdgeSAM is to transfer the capabilities of SAM into a much more compact model, which makes deployment on edge devices feasible. In particular, EdgeSAM maintains the encoder-decoder architecture of SAM and aims to preserve the performance of zero-shot interactive segmentation with box and point prompts. Our key insight is to consider prompts during knowledge distillation so that the student model receives task-specific guidance and focuses on harder training targets, such as a finer boundary. To this end, we introduce a dynamic prompt sampling strategy, which is designed to achieve three key objectives: (1) dynamically generate a diverse set of prompt combinations from the initial prompt (be it a box or a point), (2) accurately identify areas within the mask where the student model exhibits inaccuracies, thereby directing its focus to these specific segments, and (3) compel the teacher model, namely the SAM, to produce high-quality masks for more precise guidance.
Real-world
Examples
To show the practical utility of EdgeSAM, we have developed an iOS application for on-device demonstration. All examples provided below are obtained in real-time on an iPhone 13 running iOS 17. We're planning to release the iOS app to the App Store. Stay tuned!
Experimental
Results
| Method | Train Set | COCO | GFLOPs | MParam. | FPS | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| AP | APS | APM | APL | iPhone 14 | 2080 Ti | 3090 | ||||
| SAM | SA-1B | 46.1 | 33.6 | 51.9 | 57.7 | 2734.8 | 641.1 | - | 4.3 | - |
| FastSAM | 2% SA-1B | 37.9 | 23.9 | 43.4 | 50.0 | 887.6 | 68.2 | - | - | 25.0* |
| MobileSAM | 1% SA-1B | 39.4 | 26.9 | 44.4 | 52.2 | 38.2 | 9.8 | 4.9 | 103.5 | 100.0* |
| EdgeSAM (Ours) | 1% SA-1B | 42.2 | 29.6 | 47.6 | 53.9 | 22.1 | 9.6 | 38.7 | 164.3 | - |
| EdgeSAM-3x | 3% SA-1B | 42.7 | 30.0 | 48.6 | 54.5 | 22.1 | 9.6 | 38.7 | 164.3 | - |
| EdgeSAM-10x | 10% SA-1B | 43.0 | 30.3 | 48.9 | 55.1 | 22.1 | 9.6 | 38.7 | 164.3 | - |
Paper
Citation
@article{zhou2023edgesam,
title={EdgeSAM: Prompt-In-the-Loop Distillation for On-Device Deployment of SAM},
author={Zhou, Chong and Li, Xiangtai and Loy, Chen Change and Dai, Bo},
journal={arXiv preprint},
year={2023}
}
Related
Projects
